Advancing Question Answering with Decoder-Only Causal Language Models: Efficient Fine-Tuning and Inference Techniques for Large-Scale QA¶
This was a group project completed for GA Tech's CS 7643: Deep Learning. My group mates were Andrey Shor (LinkedIn) and Artem Maryanskyy (Email).
Large language models (LLMs), large-scale deep learning models using a transformer architecture, are the current state-of-the-art for processing and understanding written language. Trained on massive amounts of text-based data, these models can be used to perform a number of natural language processing (NLP) tasks, such as text generation, summarization of long texts, and translation [1]. Because these models are so versatile, it has become customary to pre-train LLMs on general, task-agnostic data and publish them for the use of multiple downstream tasks.
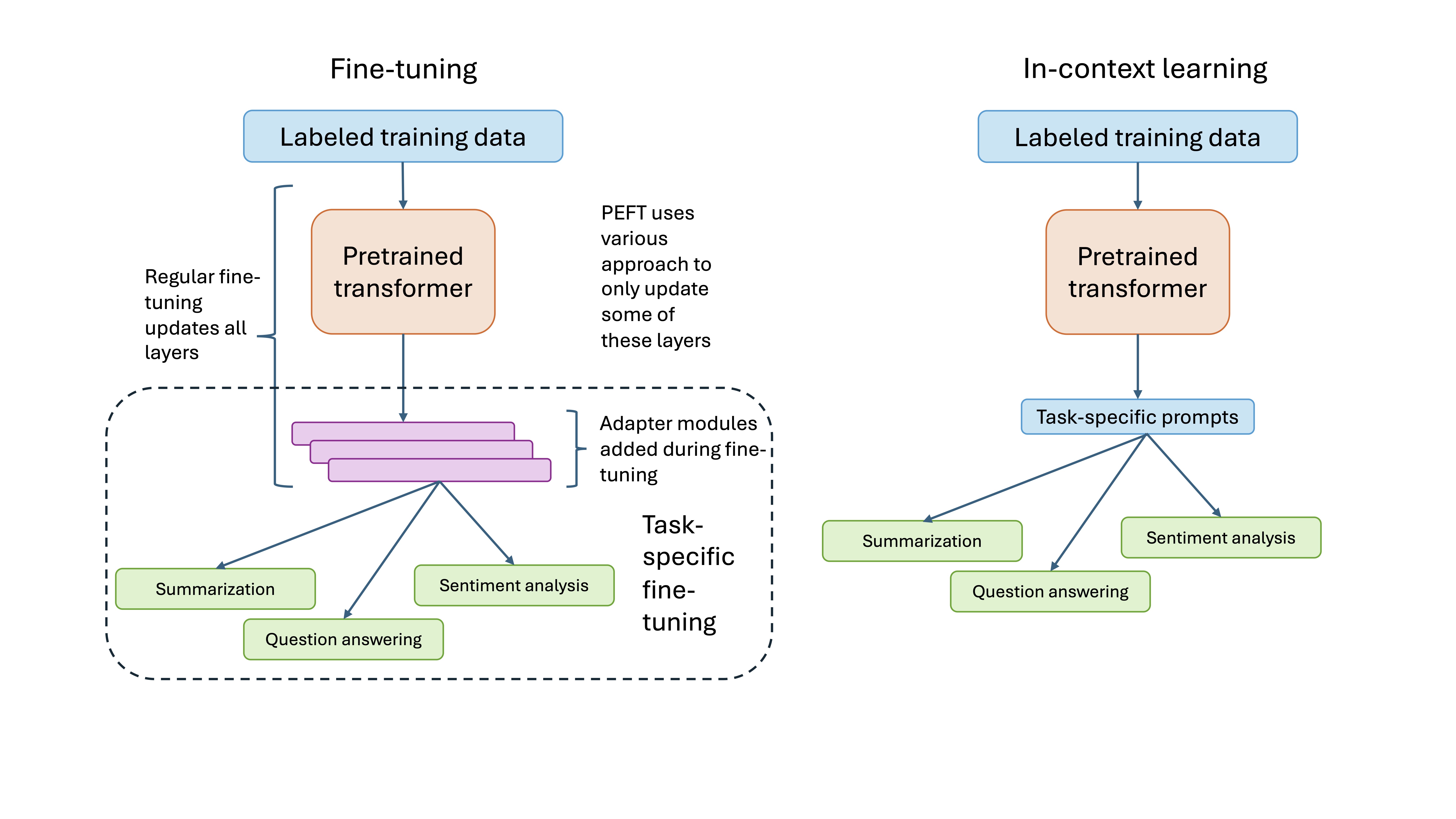
Many approaches are effective at adapting pre-trained LLMs for a specific task. This process, called fine-tuning, can be very computationally heavy when performed as a standard training process, i.e., requiring the updating of billions of model parameters. Therefore, much contemporary LLM research focuses on increasing efficiency of the fine-tuning process. One very fruitful type of approach is Parameter Efficient Fine Tuning Methods (PEFT), which improve efficiency by reducing the number of model parameters that must be updated during gradient-descent-based fine-tuning, and thereby reduce requisite memory and computation [2].
Another approach to increasing LLM efficiency is to focus on inference time. One exmaple of this is In-Context Learning (ICL) methods, which bypass gradient-descent-based fine-tuning entirely by leveraging the emergent property of LLMs that they are able to perform on previously unseen tasks after seeing some examples of that task [3]. Depending on how many (training) examples of the new task are fed to the model, the approach may be referred to as Zero-Shot, One-Shot, or Few-Shot ICL.
These are only a couple broad categories of approaches in a field that is teeming with fresh ideas and combinations of existing ideas. Given this abundance, there is a need for thorough and specific direct comparisons in order to discover the optimal combination of methods for the task-specific adaptation of pre-trained LLMs.
Project Goals¶
In this project, we employed a selection of efficiency approaches to fine-tune each of three publicly available pre-trained LLMs. By comparing the inference speed of each method and the performance of the resultant fine-tuned models, we aimed to contribute to the search for optimal fine-tuning approaches.
Models and Data Sources¶
The pre-trained models are all available on HuggingFace: the 7 Billion parameter version of Llama, the 2 Billion parameter version of Gemma, the 7 Billion parameter version of Gemma, and the 7 Billion parameter version of Mistral. All three models are pre-trained generative LLMs that use a decoder-only transformer architecture.
All fine-tuning experiments were done using the UnifiedQA dataset, which consistis of a collection of different question-answering datasets that span four formats: yes/no, multiple choice, extractive (the question is a paragraph and the answer is a substring from the paragraph), and abstractive (the question is a paragraph and the answer is something about that paragraph but is more than just a substring) [4].
A note on using decoder-only transformers for question-answering tasks: compared to a encoder-decoder architecture, in which a model explicitly learns about the dependencies between tokens in the question, via the encoder, in order to produce answers, via the decoder, decoder-only architectures generate text simply as next-word prediction (attending only to positions prior to that of the current token) [5]. Despite this, decoder-only LLMs display impressive emergent properties that allow them to be applied to many types of tasks out-of-the-box, and with fine-tuning can learn to answer questions in the format desired [5].
Efficient Fine-Tuning and Inference Details¶
Parameter Efficient Fine-Tuning (PEFT)
- Low Rank Adaptation (LoRA) introduces trainable decomposition matrices into the model and effectively performs low-rank decomposition on model parameter matrices while preserving essential information [6].
- Quantization LoRA (QLoRA) additionally quantizes the weights of the pre-trained network, meaning it converts weights from high-precision data types to low-precision data types (such as from float-32 to int-8), which compresses the model [6].
- Adaptive LorRA (AdaLoRA) adaptively assigns more or fewer rank (more or fewer parameters) to matrices with more or less importance, (addressing a LoRA shortcoming of assuming a constant importance of each weight matrix across layers by pre-specifying the rank of the decomposition matrix [7]).
Adapter-based Tuning takes the approach of adding adapter modules (new, randomly-initialized layers) to the transformer-based architecture and updating the adapter weights while keeping the pre-trained weights frozen [8].
- Infused Adapter by Inhibiting and Amplifying Inner Activations (IA)3, introduces a set of learned vectors to rescale the model’s activations, namely the keys and values in attention layers and inner products of feedforward layers [9].
Prompt-tuning reduces trainable parameters by adding discrete (or manually written) prompt tokens to the input and performing fine-tuning by updating the parameters associated with those prompts [10].
Speculative Decoding speeds up sampling from LLMs by computing tokens in parallel using several smaller, approximation models that create a number of guesses at prefixes which are then evaluated by the larger model and chosen if they don’t change the target distribution [11].
Hardware Requirements¶
We used Lambdalabs [12], which is a GPU-as-a-service provider that rents out GPUs, to perform many of the above fine-tuning methods as well as inference. In order to do so, we developed a PEFT Training CLI, uploaded it to Lambdalabs, and implemented four bash scripts to run it. The four experiments we ran with these bash scripts were QLoRA, Quantized Adalora, Quantized IA3, and Quantized Prompt Tuning. We had to run the models in quantized versions as the hardware requirements we utilized (1 x A100 GPU on Lambda Labs) did not have enough memory to be able to handle the unquantized variants during training.
We used the same A100 GPU instance for inference with the fine-tuned PEFT models, as well as for ICL and speculative decoding.
Summary of Findings¶
We implemented each PEFT, ICL, and inference-time efficiency method described above and evaluated each one by measuring the performance of the resultant models on test data and the inference-time efficiency while generating predictions.
We evaluated each approach using accuracy (Jaccard similarity), perplexity (which captures the degree of uncertainty of the model when seeing new data), and GPU throughput (number of output tokens the model generates per second).
Gemma 2B Results
| Approach | Test Accuracy | Test Avg Jaccard Similarity | GPU Throughput | Training Perplexity |
|---|---|---|---|---|
| QLoRA | 0.0 | 0.1878 | 169.6 | 24.6407 |
| AdaLoRA | 0.0 | 0.2133 | 135.0 | 638.3585 |
| (IA)^3 | 0.0 | 0.2125 | 180.3 | 35.6803 |
| Prompt Tuning | 0.0 | 0.0449 | 190.5 | 35.6803 |
Gemma 7B Results
| Approach | Test Accuracy | Test Avg Jaccard Similarity | GPU Throughput | Training Perplexity |
|---|---|---|---|---|
| QLoRA | 0.0 | 0.1878 | 169.6 | 24.6407 |
| AdaLoRA | 0.0 | 0.2133 | 135.0 | 638.3585 |
| (IA)^3 | 0.0 | 0.2125 | 180.3 | 35.6803 |
| Prompt Tuning | 0.0 | 0.0449 | 190.5 | 35.6803 |
Llama 7B Results
| Approach | Test Accuracy | Test Avg Jaccard Similarity | GPU Throughput | Training Perplexity |
|---|---|---|---|---|
| QLoRA | 0.0 | 0.1878 | 169.6 | 24.6407 |
| AdaLoRA | 0.0 | 0.2133 | 135.0 | 638.3585 |
| (IA)^3 | 0.0 | 0.2125 | 180.3 | 35.6803 |
| Prompt Tuning | 0.0 | 0.0449 | 190.5 | 35.6803 |
Mistral 7B Results
| Approach | Test Accuracy | Test Avg Jaccard Similarity | GPU Throughput | Training Perplexity |
|---|---|---|---|---|
| QLoRA | 0.0 | 0.1878 | 169.6 | 24.6407 |
| AdaLoRA | 0.0 | 0.2133 | 135.0 | 638.3585 |
| (IA)^3 | 0.0 | 0.2125 | 180.3 | 35.6803 |
| Prompt Tuning | 0.0 | 0.0449 | 190.5 | 35.6803 |
Full Project¶
Data Preprocessing¶
The raw UnifiedQA datasets were downloaded from Google storage using a script provided by Allen AI [4]. Basic preprocessing was performed to generate lowercase text .json files with ‘id’, ‘question’, and ‘answer’ keys containing lists for each data sample. Each of the three models expect a different QA format; however, these idiosyncracies are not something that is widely documented. See the links in the code below for where the method was found.
Finally, the model-specific datasets were tokenized using a HuggingFace- developed procedure that uses the pre-trained tokenizer associated with a pre-trained model hosted on HuggingFace (as were all the models we used).
import os
import json
from tqdm import tqdm
# HuggingFace packages:
from transformers import AutoTokenizer
from datasets import Dataset
def make_unified_qa_dataset(unified_datasets: list, data_path: str, data_type: str) -> dict:
'''Func to generate .json dataset with "id", "question", and "answer" keys. "id" is created for each dataset specifically
Args:
unified_datasets: a list of names of datasets within the unified datasets list
e.g. UNIFIED_DATASETS = ["narrativeqa",
"ai2_science_middle", "ai2_science_elementary",
"arc_hard", "arc_easy",
"mctest_corrected_the_separator",
"squad1_1", "squad2","boolq",
"race_string","openbookqa"]
data_path: local path to store json
data_type: which section of dataset to process; "train", "dev", or "test"
'''
assert data_type in ["train", "dev", "test"], "data_type must be 'train', 'dev', or 'test'"
unified_dataset = {}
for dataset in unified_datasets:
curr_data_path = os.path.join(data_path, dataset, f"{data_type}.tsv")
unified_dataset[dataset] = {"id": [], "question": [], "answer": []}
with open(curr_data_path, "r", encoding="utf-8") as f:
cnt = 0
for line in f:
if line.strip():
question, answer = line.strip().split("\t")
unified_dataset[dataset]["id"].append(f"{dataset}-{data_type}-{cnt}")
unified_dataset[dataset]["question"].append(question)
unified_dataset[dataset]['answer'].append(answer)
cnt += 1
return unified_dataset
def preprocess_unified_qa_dataset(datasets: dict, append_instruction_gemma: bool=False, append_instruction_llama: bool=False,
append_instruction_mistral: bool=False, append_bos: bool=False, append_s:bool=False) -> dict:
'''Func to process data into its model-specific format; must create a version for each model bc
each model expects a different chat structure'''
assert sum([append_instruction_gemma, append_instruction_llama, append_instruction_mistral]) == 1, \
"Exactly one 'append_instruction...' parameter must be true"
assert sum([append_bos, append_s]) <= 1, \
"At most one of 'append_bos' or 'append_s' can be true"
preprocessed_unified_dataset = {}
for dataset in datasets.keys():
preprocessed_unified_dataset[dataset] = {"id": [], "question": [], "answer": []}
preprocessed_unified_dataset[dataset]['id'] = [id for id in datasets[dataset]['id']]
preprocessed_unified_dataset[dataset]['question'] = [question.lower().strip() for question in datasets[dataset]['question']]
preprocessed_unified_dataset[dataset]['answer'] = [answer.lower().strip() for answer in datasets[dataset]['answer']]
if append_instruction_gemma: # For Gemma Models: https://huggingface.co/google/gemma-7b/discussions/62
preprocessed_unified_dataset[dataset]['question'] = ["<start_of_turn>user\n" + question + "<end_of_turn>\n\n" for question in preprocessed_unified_dataset[dataset]['question']]
preprocessed_unified_dataset[dataset]['answer'] = ["<start_of_turn>model\n" + answer + "<end_of_turn>" for answer in preprocessed_unified_dataset[dataset]['answer']]
if append_instruction_llama: # For Llama 2: https://huggingface.co/docs/optimum-neuron/en/tutorials/fine_tune_llama_7b or https://github.com/mallorbc/llama_dataset_formats/blob/26b29649dca39552e2ecb9d7041468488b9b0f32/README.md
preprocessed_unified_dataset[dataset]['question'] = ["Input:\n" + question for question in preprocessed_unified_dataset[dataset]['question']]
preprocessed_unified_dataset[dataset]['answer'] = ["Output:\n" + answer for answer in preprocessed_unified_dataset[dataset]['answer']]
if append_instruction_mistral: # For Mistral 7b: https://www.promptingguide.ai/models/mistral-7b
preprocessed_unified_dataset[dataset]['question'] = ["[INST] " + question + " [/INST]" for question in preprocessed_unified_dataset[dataset]['question']]
preprocessed_unified_dataset[dataset]['answer'] = [answer for answer in preprocessed_unified_dataset[dataset]['answer']]
if append_bos:
preprocessed_unified_dataset[dataset]['question'] = ["<bos>"+question for question in preprocessed_unified_dataset[dataset]['question']]
if append_s:
preprocessed_unified_dataset[dataset]['question'] = ["<s>"+question + '\n\n' for question in preprocessed_unified_dataset[dataset]['question']]
preprocessed_unified_dataset[dataset]['text'] = [q + " " + a for q, a in zip(preprocessed_unified_dataset[dataset]["question"], preprocessed_unified_dataset[dataset]["answer"])]
return preprocessed_unified_dataset
def tokenize_dataset(preprocessed_unified_dataset: dict, model_name: str, pad_token: bool, pad_side:str='right') -> dict:
'''Func to tokenize the processed dataset using a pretrained HuggingFace tokenizer
Args:
preprocessed_unified_dataset: output from "preprocess_unified_qa_dataset"
model_name: one of "google/gemma-7b", "mistralai/Mistral-7B-v0.1", "meta-llama/Llama-2-7b-hf"
pad_token: Whether to pad with EOS token
pad_sice: which side to pad with pad token
'''
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
if pad_token:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = pad_side
for dataset in preprocessed_unified_dataset.keys():
preprocessed_unified_dataset[dataset]['input_ids'] = [tokenizer(item, return_tensors='pt').input_ids.tolist() for item in preprocessed_unified_dataset[dataset]['text']]
return preprocessed_unified_dataset
def load_tokenized_dataset(file_path:str) -> Dataset:
'''From a given local file path, create a HuggingFace Dataset object from a .json file with
"id", "questions", "answers", "text" and "input_ids" keys'''
data_dict = {}
with open(file_path, 'r') as fp:
id, questions, answers, text, input_id = json.load(fp)
data_dict['id'] = id
data_dict['questions'] = questions
data_dict['answers'] = answers
data_dict['text'] = text
data_dict['input_ids'] = input_id
return Dataset.from_dict(data_dict)
Efficient Fine-Tuning¶
Each efficiency method that involves further training and/or modification of the base model in some way was performed on a Lambdalabs instance. Experiments were implemented via a Python CLI tool that performed the folliowng steps:
- Load the specified model (Gemma-2b, Gemma-7b, Llama-7b, and Mistral-7b) and corresponding tokenizer from HuggingFace.
- Load a configuration for the specified PEFT approach, which specifies required parameters and hyperparameters that vary from approach to approach.
- Train the model using the PEFT hyperparameters and the general training hyperparameters mentioned below.
- When training is complete, save the trained model and the training losses.
Below is a description of each approach-specific hyperparameter:
| Approach | Hyperparameter | Description |
|---|---|---|
| LoRA, QLoRa, AdaLoRA | r | Rank; the size of the low-rank matrices used to decompose the weight ma- trix. |
| alpha | Scaling factor applied to the learned decomposition matrices. | |
| bias | Whether “none”, “all”, or only the LoRA bias parameters should be trained. | |
| dropout | The dropout probability for LoRA layers. | |
| AdaLoRA | target_r | The target average rank of incremental matrix. |
| init_r | The initial rank for each incremental matrix. | |
| tinit | The steps of initial fine-tuning warmup. | |
| tfinal | The step of final fine-tuning. | |
| QLoRA Quantization | load_in_4bit | Whether to quantize the model to 4-bits when you load it set [14]. |
| bnb_4bit_compute_dtype | The computational type which might be different than the input time. Use torch.bfloat16 for speedups [14]. | |
| bnb_4bit_use_double_quant | Whether to use a nested quantization scheme to quantize the already quan- tized weights set [14]. | |
| (IA)^3 | target_modules | The layers to apply rescaling to [9,15]. |
| Prompt Tuning | prompt_tuning_init | The initialization of the prompt embedding [4]. |
| prompt_tuning_init_text | The text to initialize the prompt embedding [4]. | |
| prompt_tuning_init_text | The text to initialize the prompt embedding [4]. |
While I didn't include the CLI in this notebook, below are a number of functions used to load the models, training configs, and to call the training procedures.
import torch
import time
# HuggingFace packages:
from datasets import Dataset
import datasets
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training, IA3Config, AdaLoraConfig, PromptTuningConfig
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, pipeline
from trl import SFTTrainer
# for lora and qlora: https://www.databricks.com/blog/efficient-fine-tuning-lora-guide-llms
def prepare_lora_config(r:int=8, lora_alpha:int = 8, lora_dropout:float=.05, bias='none',
targets:str='linear', task_type:str='CAUSAL_LM'): # can also take attn
assert targets in ['linear', 'attn'], "Targets must be 'linear' or 'attn'."
if targets == 'linear': # per literature review, best performance is when LoRA and QLoRA are applied to lora linear layers
target_modules = ['q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj','lm_head']
elif targets == 'attn':
target_modules = ["q_proj", "v_proj"]
return LoraConfig(r=r, target_modules=target_modules, lora_alpha=lora_alpha,
lora_dropout=lora_dropout, bias=bias, task_type=task_type)
# for IA3: https://huggingface.co/docs/peft/en/package_reference/ia3
def prepare_ia3_config(r:int=8, targets:str='linear', feedforward_modules=None,
task_type:str='CAUSAL_LM'): # can also take attn
assert targets in ['linear', 'attn'], "Targets must be 'linear' or 'attn'."
if targets == 'linear':
target_modules = ['q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj','lm_head']
elif targets == 'attn':
target_modules = ["q_proj", "v_proj"]
return IA3Config(peft_type="IA3", task_type=task_type, target_modules=target_modules,
feedforward_modules=feedforward_modules)
# for AdaLora: https://huggingface.co/docs/peft/en/package_reference/adalora
def prepare_adalora_config(r:int=8, lora_alpha:int = 8, lora_dropout:float=.05, bias='none',
targets:str='linear', task_type:str='CAUSAL_LM'): # can also take attn
assert targets in ['linear', 'attn'], "Targets must be 'linear' or 'attn'."
if targets == 'linear': # per literature review, best performance is when LoRA and QLoRA are applied to lora linear layers
target_modules = ['q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj','lm_head']
elif targets == 'attn':
target_modules = ["q_proj", "v_proj"]
return AdaLoraConfig(peft_type="ADALORA", task_type=task_type, r=r, target_modules=target_modules,
lora_alpha=lora_alpha, lora_dropout=lora_dropout, bias=bias)
# https://huggingface.co/docs/peft/en/package_reference/prompt_tuning
# https://huggingface.co/docs/peft/main/en/task_guides/clm-prompt-tuning
def prepare_prompt_tuning_config(task_type:str='CAUSAL_LM', num_virtual_tokens:int = 8,
prompt_tuning_init_task:str = None, tokenizer_model:str=None):
return PromptTuningConfig(task_type=task_type, prompt_tuning_init="TEXT",
num_virtual_tokens=num_virtual_tokens, prompt_tuning_init_text=prompt_tuning_init_task,
tokenizer_name_or_path=tokenizer_model)
def prepare_peft_model(base_model:AutoModelForCausalLM, tokenizer:AutoTokenizer, use_cache:bool=False) -> PeftModel:
'''Creates a PeftModel HuggingFace object by wrapping a pretrained model in some functionality
that is required for Peft training'''
peft_model = prepare_model_for_kbit_training(base_model)
peft_model.config.pad_token_id = tokenizer.pad_token_id
peft_model.use_cache = use_cache
return peft_model
def setup_trainer(model:PeftModel, ds:dict[Dataset], tokenizer:AutoTokenizer, peft_config, custom_args=None) -> SFTTrainer:
'''Initialize a HuggingFace SFTTrainer object
Args:
model: output from prepare_peft_model
ds: dict with "train" and "dev" keys, each of which are Dataset objects
tokenizer: pretrained tokenizer object
peft_config: one of a number of configs that can work with a trainer; see funcs above
custom_args:
'''
default_args = {
"evaluation_strategy": "steps",
"do_eval": True,
"optim": "paged_adamw_32bit",
"per_device_train_batch_size": 8,
"per_device_eval_batch_size": 8,
"log_level": "debug",
"save_strategy": "steps",
"save_steps": 25,
"logging_steps": 25,
"learning_rate": 2e-5,
"group_by_length": True,
"eval_steps": 50,
"max_steps": 200,
"warmup_steps": 30,
"lr_scheduler_type": "linear",
"weight_decay":.001,
"max_grad_norm":.3,
"report_to":"tensorboard"}
if custom_args:
default_args.update(custom_args)
training_arguments = TrainingArguments(**default_args)
trainer = SFTTrainer(
model=model,
dataset_text_field="text",
train_dataset=ds['train'],
eval_dataset=ds['dev'],
peft_config=peft_config,
max_seq_length=512,
tokenizer=tokenizer,
args=training_arguments,)
return trainer
Training metrics¶
Below is an example of the output saved during the training epochs. The loss is the Cross Entropy Loss.
loss = [{'loss': 2.7495,
'grad_norm': 16.782007217407227,
'learning_rate': 1.7647058823529414e-05,
'epoch': 0.0010210749877471001,
'step': 50},
{'loss': 2.2949,
'grad_norm': 12.598627090454102,
'learning_rate': 1.1764705882352942e-05,
'epoch': 0.0020421499754942002,
'step': 100},
{'loss': 2.2661,
'grad_norm': 14.374794006347656,
'learning_rate': 5.882352941176471e-06,
'epoch': 0.0030632249632413003,
'step': 150},
{'loss': 2.2124,
'grad_norm': 13.702934265136719,
'learning_rate': 0.0,
'epoch': 0.0040842999509884004,
'step': 200},
{'train_runtime': 1797.4708,
'train_samples_per_second': 0.89,
'train_steps_per_second': 0.111,
'total_flos': 2.588837616554803e+16,
'train_loss': 2.38071720123291,
'epoch': 0.0040842999509884004,
'step': 200}]
In-Context Learning¶
As mentioned previously, ICL is a method for adapting pre-trained LLMs to specific tasks that leverages the property of LLMs that they are able to perform on previously unseen tasks after seeing some examples of that task.
For Zero-Shot ICL, we didn't give the model any examples of how to perform the task, but simply inserted the prompt "Answer the quesion truthfully", to clue the model that it is a QA task. In the k-Shot cases, we inserted the prompt "Answer the question truthfully. Follow these examples:" followed by k question-answer pairs in the model-specific chat format.
Below are the utility functions used to insert zero or k-shot prompts plus examples into the proper location in the question, depending on the model.
For all of the following evaluation using the fine-tuned models, we used ICL to the extent that we at least used the basic Zero-Shot prompt.
def process_samples(sample_data:Dataset, model_name:str, prompt_insert:str, tokenizer:AutoTokenizer) -> Dataset:
'''Do the actual insertion of the prompt into each example in a sample dataset
Args:
sample_data: Dataset
model_name: one of "google/gemma-7b", "meta-llama/Llama-2-7b-hf", "mistralai/Mistral-7B-v0.1"
prompt_insert: preprocessed complete prompt
tokenizer: pretrained tokenizer
'''
assert model_name in ["google/gemma-7b", "meta-llama/Llama-2-7b-hf", "mistralai/Mistral-7B-v0.1"]
model_to_insert_point = {
'google/gemma-7b': "user",
'meta-llama/Llama-2-7b-hf': "<s>",
'mistralai/Mistral-7B-v0.1': "[INST]"}
original_dataset, new_tokenizations = [], []
for example in sample_data:
text = example['questions']
insertion_point = text.find(model_to_insert_point[model_name]) + len(model_to_insert_point[model_name])
new_text = text[:insertion_point] + " " + prompt_insert + " " + text[insertion_point:]
inputs = tokenizer(new_text, return_tensors="pt")
original_dataset.append(example['id'].split('-')[0])
new_tokenizations.append(inputs.input_ids)
processed_samples = {'prompt_tokenizations': new_tokenizations, 'original_dataset': original_dataset}
out = Dataset.from_dict(processed_samples)
return out
def preprocess_prompt_icl(hf_model:str, ds:Dataset, experiment:str, k_shot:int=1, prompt_insert:str= "Answer this question truthfully",
max_k_shot_token_length:int=200, seed:int=42, sample:int=1000) -> Dataset:
''' Add a prompt or prompt plus examples to a point within each example in a dataset
Args:
hf_model: one of "google/gemma-7b", "meta-llama/Llama-2-7b-hf", "mistralai/Mistral-7B-v0.1";
used to load the model-specific pretrained tokenizer and to determine at which point in the question the
prompts should be inserted
ds: processed Dataset object
experiment: one of "k_shot" or "zero_shot" to determine how to add prompts to the examples in the dataset
k_shot: for the "k_shot" case, how many examples to add
prompt_insert: the prompt to put before the question or before the examples
max_k_shot_token_length: the max number of tokens allowed for the example to be included in k-shot preprocessing
sample: how many examples to take from ds
'''
assert k_shot in ["k_shot", "zero_shot"]
ds = ds.shuffle(seed=seed)
eval_sample = ds.select(range(sample))
loaded_tokenizer = AutoTokenizer.from_pretrained(hf_model, device_map={"": 0})
def filter_by_token_length(example) -> bool:
'''remove examples from the dataset that are longer than max_k_shot_token_length'''
tokens = loaded_tokenizer(example['text'], return_tensors="pt", truncation=False)
return tokens.input_ids.size(1) <= max_k_shot_token_length
print(f'Running prompt injection for: {experiment}')
if experiment == 'zero_shot':
prompt_insert = f'{prompt_insert}:'
results = process_samples(eval_sample, hf_model, prompt_insert, loaded_tokenizer)
elif experiment == 'k_shot':
filtered_dataset_for_k_shot = ds.filter(filter_by_token_length).shuffle(seed=7)
if len(filtered_dataset_for_k_shot) < k_shot:
raise ValueError(f"Dataset has less than {k_shot} examples")
# Add examples after base prompt
prompt_insert = f"{prompt_insert}. Follow these examples:"
for q, a in zip(filtered_dataset_for_k_shot['questions'][:k_shot], filtered_dataset_for_k_shot['answers'][:k_shot]):
prompt_insert += "\n"
prompt_insert += (q + a)
prompt_insert += "\n"
prompt_insert += 'Question:'
results = process_samples(eval_sample, hf_model, prompt_insert, loaded_tokenizer)
eval_sample = datasets.concatenate_datasets([eval_sample, results], axis=1)
return eval_sample
Inference and Evaluation¶
For each model, we evaluated each fine-tuned version on the test dataset, which contains samples across the 11 UnifiedQA datasets.
For each sample, the question text, preprocessed to have the model-specific chat tags, was fed to the model and the generated text was collected as the prediction. The answer was then stripped out of that prediction, which was also formatted according to the model-specific chat format, saved, and compared to the ground-truth (human generated) answers to each question.
Below are a few functions used for loading the trained model, predicting using it, and stripping the answers, and saving the predictions for evaluation.
import re
# HuggingFace packages:
import datasets
from peft import AutoPeftModelForCausalLM
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
CONFIG_8BITS = BitsAndBytesConfig(load_in_8bit=True)
def load_model(base_model:str, bnb_config:BitsAndBytesConfig=None, access_token:str=None,
use_cache:bool=False, pretraining_tp:int=1) -> AutoModelForCausalLM:
'''Load a pretrained HuggingFace model and Tokenizer using a bits and bytes config'''
base_model_loaded = AutoModelForCausalLM.from_pretrained(
base_model, token=access_token, quantization_config=bnb_config, device_map={"": 0})
base_model_loaded.config.use_cache = use_cache
base_model_loaded.config.pretraining_tp = pretraining_tp
tokenizer = AutoTokenizer.from_pretrained(base_model, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
return base_model_loaded, tokenizer
def load_model_for_eval(base_model_name:str, local_trained_model_path:str, quant_config=CONFIG_8BITS) -> AutoModelForCausalLM:
'''Load a pretrained HuggingFace model and Tokenizer using a bits and bytes config, don't include settings req'd for training'''
peft_model = AutoPeftModelForCausalLM.from_pretrained(
local_trained_model_path, device_map={"": 0}, quantization_config=quant_config)
tokenizer = AutoTokenizer.from_pretrained(base_model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
return peft_model, tokenizer
def predict(trained_model:AutoModelForCausalLM, tokenizer:AutoTokenizer, eval_sample:Dataset, prompted:bool=False):
'''Create a list of predictions using a fine-tuned model on a eval dataset
Args:
trained_model: fine-tuned model
tokenizer: pretrained tokenizer
eval_sample: preprocessed data; must have "prompt_tokenizations" column if prompted=True
prompted: whether to use the prompt_tokenizations column for question-asking
'''
if prompted==True:
assert 'prompt_tokenizations' in list(eval_sample.features.keys()), f"Eval Data needs the following column: 'prompt_tokenizations', but instead has { list(eval_sample.features.keys()) }"
token_col = 'prompt_tokenizations'
else:
assert 'input_ids' in list(eval_sample.features.keys()), f"Eval Data needs the following column: 'input_ids', but instead has { list(eval_sample.features.keys()) }"
token_col = 'input_ids'
if torch.cuda.is_available():
print('cuda is available')
eval_sample.set_format("torch", device="cuda")
else:
eval_sample.set_format("torch")
predictions = []
latencies = [] # collect how long each prediction takes
for inp in eval_sample[token_col]:
start = time.time()
outp = trained_model.generate(inp, max_new_tokens=20, output_scores=True)
end = time.time()
pred = tokenizer.batch_decode(outp, skip_special_tokens=True)
predictions.append(pred[0])
latencies.append(end - start) # calculate latency
return predictions, latencies
def strip_output_text(output:str, model_name:str) -> str:
'''Post-process prediction text'''
out = output
xplicit_answer_idx = out.find("Answer")
if xplicit_answer_idx > 0:
start_idx = xplicit_answer_idx + len("Answer")
if model_name == 'google/gemma-7b' or model_name == 'google/gemma-2b':
model_start = out.find("model")
if model_start > 0:
start_idx = model_start + len("model")
else:
start_idx = 0
out = out[start_idx:]
out = re.sub('[^a-zA-Z\s]+', '', out)
out = re.sub('\s+', ' ', out).strip()
return out
elif model_name == 'meta-llama/Llama-2-7b-hf':
start_idx = out.find("Output:") + len("Output:")
end_idx = out.find("\n\n", start_idx)
if end_idx == -1:
end_idx = len(out)
out = out[start_idx:end_idx].strip()
out = re.sub('[^a-zA-Z\s]+', '', out)
out = re.sub(r'\bbinbash\b|\becho\b', '', out, flags=re.IGNORECASE)
out = re.sub('\s+', ' ', out).strip()
return out
elif model_name == 'mistralai/Mistral-7B-v0.1':
start_idx = out.find("Output:") + len("Output:")
end_idx = out.find("\n\n", start_idx)
if end_idx == -1:
end_idx = len(out)
out = out[start_idx:end_idx].strip()
out = re.sub('[^a-zA-Z\s]+', '', out)
out = re.sub(r'\bbinbash\b|\becho\b', '', out, flags=re.IGNORECASE)
out = re.sub('\s+', ' ', out).strip()
return out
else:
print("model_name should be one of 'google/gemma-7b', 'google/gemma-2b', 'meta-llama/Llama-2-7b-hf', or 'mistralai/Mistral-7B-v0.1'")
def strip_answers(answer_text:str, model_name:str) -> str:
'''Post-process ground truth answers from each dataset'''
out = answer_text
if model_name == 'google/gemma-7b':
for strp in ['<start_of_turn>model\n', '<end_of_turn>']:
out = out.replace(strp, '')
elif model_name == 'meta-llama/Llama-2-7b-hf':
out = out.replace("Output:\n", '')
out = re.sub('[^a-zA-Z\s]+', '', out)
out = re.sub('\s+', ' ', out).strip()
return out
def add_dataset_name_col(ds:Dataset) -> Dataset:
'''Convenience func to add col that indicates which original dataset each prediction
and ground truth came from'''
original_dataset = []
for example in ds:
original_dataset.append(example['id'].split('-')[0])
eval_sample = datasets.concatenate_datasets([ds, Dataset.from_dict({'original_dataset': original_dataset})], axis=1)
return eval_sample
def prediction_wrapper(trained_model:AutoModelForCausalLM, tokenizer:AutoTokenizer, ds:Dataset,
model_name:str, add_prompt:str='', sample:int=1000, seed:int=42) -> Dataset:
'''Predict using fine-tuned dataset and post-process both predictions and ground truth, creating
a new dataset for evaluation
Args:
trained_model: fine-tuned model
tokenizer: pretrained tokenizer
ds: processed Dataset object
model_name: one of "google/gemma-7b", "meta-llama/Llama-2-7b-hf", "mistralai/Mistral-7B-v0.1"
add_prompt: prompt to add
sample: how many example from eval dataset to predict on
'''
if len(add_prompt) > 0 and sample > 0:
eval_sample = preprocess_prompt_icl(
model_name, tokenizer, ds, experiment='zero_shot', prompt_insert=add_prompt, sample=sample, seed=seed)
elif len(add_prompt) == 0 and sample > 0:
ds = ds.shuffle(seed=seed)
sample_data = ds.select(range(sample))
eval_sample = add_dataset_name_col(sample_data)
elif len(add_prompt) > 0 and sample == 0: # if sample == 0, use the whole dataset
eval_sample = preprocess_prompt_icl(
model_name, tokenizer, ds, experiment='zero_shot', prompt_insert=add_prompt, sample=ds.shape[0], seed=seed)
else:
eval_sample = add_dataset_name_col(ds)
print("eval_sample generated")
predictions, latencies = predict(trained_model, tokenizer, eval_sample, prompted=add_prompt)
print("predictions generated")
predictions = [strip_output_text(s, model_name) for s in predictions]
answers_stripped = [strip_answers(s, model_name) for s in eval_sample['answers']]
pred_ds = Dataset.from_dict({
'predictions': [p.lower() for p in predictions],
'ground_truth':answers_stripped,
'original_dataset':eval_sample['original_dataset'],
'latencies': latencies})
return pred_ds
Below is the process of calling the above functions in the full inference procedure.
base_path = f'{os.getcwd()}/temp/Efficient-LLM-Benchmark'
local_models_path = f'{base_path}/Experiments/trained_models'
gcp_paths = [
# 'gemma_2b_qlora_4bits_norm_nested_outputs/gemma_2b_qlora_4bits_norm_nested_final/',
# 'gemma_7b_qlora_4bits_norm_nested_outputs/gemma_7b_qlora_4bits_norm_nested_final',
# 'llama2_7b_qlora_4bits_norm_nested_outputs/llama2_7b_qlora_4bits_norm_nested_final',
'mistral_7b_qlora_4bits_norm_nested_outputs/mistral_7b_qlora_4bits_norm_nested_final'
]
# base_model_name = "google/gemma-2b"
# base_model_name = "google/gemma-7b"
# base_model_name = 'meta-llama/Llama-2-7b-hf'
base_model_name = 'mistralai/Mistral-7B-v0.1'
base_model_test_data_map = {
"google/gemma-2b": 'Gemma_NEW',
"google/gemma-7b": 'Gemma_NEW',
'meta-llama/Llama-2-7b-hf': 'Llama_NEW',
'mistralai/Mistral-7B-v0.1': 'Mistral_NEW'
}
base_model_local_model_map = {
"google/gemma-2b": 'gemma_2b_qlora_4bits_norm_nested_outputs/gemma_2b_qlora_4bits_norm_nested_final/',
"google/gemma-7b": 'gemma_7b_qlora_4bits_norm_nested_outputs/gemma_7b_qlora_4bits_norm_nested_final',
'meta-llama/Llama-2-7b-hf': 'llama2_7b_qlora_4bits_norm_nested_outputs/llama2_7b_qlora_4bits_norm_nested_final',
'mistralai/Mistral-7B-v0.1': 'mistral_7b_qlora_4bits_norm_nested_outputs/mistral_7b_qlora_4bits_norm_nested_final'
}
gcp_path = base_model_local_model_map[base_model_name]
local_trained_model_path = f'{local_models_path}/{gcp_path}'
test_data = load_tokenized_dataset(os.path.join(
f"{base_path}/UnifiedQA Data Curation/tokenized_NEW/{base_model_test_data_map[base_model_name]}",
"test.json"))
peft_model, tokenizer = load_model_for_eval(base_model_name, local_trained_model_path)
# Batched predictions
BATCH_SIZE = 50
for i in range(500, 1000, BATCH_SIZE):
start_time = time.time()
s = test_data.select(range(i, i+BATCH_SIZE)) # create batch
pred_ds = prediction_wrapper(
peft_model, tokenizer, s,
base_model_name, add_prompt='', sample=BATCH_SIZE, # no prompt is added
save_path=f'{base_path}/Experiments/predictions/{gcp_path}/predictions_batch_{i}.json')
pred_ds['predictions'][:10]
pred_ds['ground_truth'][:10]
Speculative Decoding¶
As mentioned previously, Speculative Decoding is an algorithm that speeds up sampling from LLMs by computing tokens in parallel using several smaller, approximation models that create a number of guesses at prefixes which are then evaluated by the larger model and chosen if they don’t change the target distribution [13]. We implement speculative decoding by using a 2 billion parameter version of the Gemma model, fine-tuned with QLoRA to create speculative prefixes for the 7 billion parameter Gemma to evaluate directly in the inference/text generation stage.
def speculative_decoding(full_model:AutoModelForCausalLM, tokenizer:AutoTokenizer,
assistant_model:AutoModelForCausalLM, eval_sample:Dataset):
'''Create a list of predictions using a fine-tuned smaller model and a larger pre-trained model
(that is not finetuned) on a eval dataset
Args:
full_model: pre-trained model
tokenizer: pretrained tokenizer
assistant_model: fine-tuned model
eval_sample: preprocessed data; must have "prompt_tokenizations" column if prompted=True
'''
predictions = []
latencies = [] # collect how long each prediction takes
for inp in eval_sample['input_ids']:
start = time.time()
outp = full_model.generate(inp, assistant_model=assistant_model, max_new_tokens=20, output_scores=True)
end = time.time()
pred = tokenizer.batch_decode(outp, skip_special_tokens=True)
predictions.append(pred[0])
latencies.append(end - start)
return predictions, latencies
def spec_decod_wrapper(trained_model:AutoModelForCausalLM, tokenizer:AutoTokenizer,
assistant_model:AutoModelForCausalLM, ds:Dataset, model_name:str, sample:int=1000, seed:int=42):
'''Predict using speculative decoding approach and post-process both predictions and ground truth, creating
a new dataset for evaluation
Args:
trained_model: pre-trained model
tokenizer: pretrained tokenizer
assistant_model: fine-tuned model
ds: processed Dataset object
model_name: one of "google/gemma-7b", "meta-llama/Llama-2-7b-hf", "mistralai/Mistral-7B-v0.1"
sample: how many example from eval dataset to predict on
'''
if sample > 0:
ds = ds.shuffle(seed=seed)
sample_data = ds.select(range(sample))
eval_sample = add_dataset_name_col(sample_data)
else:
eval_sample = add_dataset_name_col(ds)
print("eval_sample generated")
predictions, latencies = speculative_decoding(trained_model, tokenizer, assistant_model, eval_sample)
print("predictions generated")
predictions = [strip_output_text(s, model_name) for s in predictions]
answers_stripped = [strip_answers(s, model_name) for s in eval_sample['answers']]
pred_ds = Dataset.from_dict({
'predictions': [p.lower() for p in predictions],
'ground_truth':answers_stripped,
'original_dataset':eval_sample['original_dataset'],
'latencies': latencies})
return pred_ds
CONFIG_4BITS = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)
large_model, tokenizer = load_model(
base_model=base_model_name, bnb_config=CONFIG_4BITS, use_cache=False, pretraining_tp=1)
assistant_model = AutoPeftModelForCausalLM.from_pretrained(
local_trained_model_path, device_map={"": 0}, quantization_config=CONFIG_4BITS)
# Batched predictions
BATCH_SIZE = 50
for i in range(0, 500, BATCH_SIZE):
start_time = time.time()
s = test_data.select(range(i, i+BATCH_SIZE)) # create batch
pred_ds = spec_decod_wrapper(
large_model, tokenizer, assistant_model, s,
base_model_name, sample=BATCH_SIZE,# no prompt is added
save_path=f'{base_path}/Experiments/predictions/spec_decod/gemma_7b/assistant_qlora_gemma_2b/predictions_batch_{i}.json')
Metrics¶
The metrics we used to evaluate the success of each method are accuracy, perplexity, and GPU throughput.
Accuracy measures how many correct outputs the model produces [16]. We calculated Jaccard similarity between each answer generated during testing with the ground truth answer. Jaccard similarity is the number of common tokens between the two strings divided by the total length of the longer string [17]. A Jaccard similarity of 1 would indicate a perfect match and thus count as a “correct” output. Because this is a stringent criteria for success in natural language understanding, we also report average Jaccard similarity across the test set for each fine-tuning approach on each model.
GPU Throughput is simply the number of output tokens the model generates per second and is higher for models with higher inference-time efficiency [18]. In order to measure throughput, we recorded the time required for each batch of inference tokens to be produced (latency in seconds) and then divided the number of produced tokens by that latency [19].
import evaluate
rouge = evaluate.load("rouge")
def compute_accuracy(scores:list) -> float:
num_correct = 0
for score in scores:
if score == 1:
num_correct += 1
accuracy = ((num_correct) / len(scores))
return accuracy
# Rouge is a similarity measure based on longest common subsequence ; used for summarization tasks
def compute_rouge(predictions:list, ground_truth:list) -> float:
print('computing similarity for summarization')
scores = rouge.compute(predictions=predictions, references=ground_truth, use_aggregator=False)
return scores['rougeL'] # longest common subsequence-based ROUGE
def jaccard(str1:str, str2:str) -> float:
'''Compute jaccard between two strings: Numb common token between two strings'''
if str1 == str2:
return 1.0
if " " in str1 or " " in str2:
str1_split = str1.split(" ")
str2_split = str2.split(" ")
overlap = list(set(str1_split) & set(str2_split))
return len(overlap) / max(len(str1_split), len(str2_split))
else:
return 0.0
def compute_similarity(predictions:list, ground_truth:list):
'''Apply jaccard similarity for multiple choice questions to get evaluation scores'''
print('computing similarity for multiple choice')
scores = []
for p, l in zip(predictions, ground_truth):
scores.append(jaccard(p,l))
return scores
def compute_scores(original_dataset:str, predictions:list, ground_truth:list):
'''Compute scores across a eval dataset
Args:
original_dataset: one of the keys in the ds_metric_map
precitions: list of predictions
ground_truth: list of correct answers
'''
ds_metric_map = { # which original dataset has which type of question -> determines which metric to use
'ai2_science_elementary': 'mc', # mc is multiple choice
'ai2_science_middle': 'mc',
'arc_easy': 'mc',
'arc_hard': 'mc',
'narrativeqa': 'rouge',
'openbookqa' : 'mc',
'race_string': 'mc'}
assert original_dataset in ds_metric_map, f"Please define a metric mapping for dataset {original_dataset}"
metric = ds_metric_map[original_dataset]
if metric == 'rouge':
scores = compute_rouge(predictions, ground_truth)
elif metric == 'mc':
scores = compute_similarity(predictions, ground_truth)
return scores
def throughput(latencies:list, predictions:list):
'''Compute throughput as average of the latency of each token was generated '''
print('computing throughput')
through_put = []
for l, p in zip(latencies, predictions):
output_tokens = len(p)
through_put.append(output_tokens / l) # how long did each token take to be generated?
avg_through_put = sum(through_put) / len(through_put) #
return avg_through_put
def evaluate_predictions(pred_ds:Dataset):
'''Wrapper func to compute accuracy, throughput, and score for a set of predictions
Args:
pred_ds: should contain ['predictions', 'ground_truth', 'original_dataset', 'latencies'] keys
'''
assert list(pred_ds.features.keys()) == ['predictions', 'ground_truth', 'original_dataset', 'latencies'], f"Prediction dataset must have ['predictions', 'ground_truth', 'original_dataset'] in columns, currently has {list(pred_ds.features.keys()) }."
# Concatenate evaluations per dataset because each one could have something slightly different happening
# depending on what type of question/answer is in that dataset (namely summarization vs multiple choice)
original_datasets = set(pred_ds['original_dataset'])
filt = {}
for ds in original_datasets:
filt[ds] = pred_ds.filter(lambda ex: ex['original_dataset'] == ds)
scores = []
for ds, data in filt.items():
scores.extend(compute_scores(ds, data['predictions'], data['ground_truth']))
accuracy = compute_accuracy(scores)
tp = throughput(pred_ds['latencies'], pred_ds['predictions'])
return scores, accuracy, tp
Perplexity¶
Perplexity captures the degree of uncertainty of the model when seeing new data, and the lower the perplexity the better [20]. Mathematically, it is the exponentiated average negative log-likelihood of a sequence [21]. The log-likelihood of a sequence is the sum of the likelihoods of each item in the sequence conditioned on the previous items in the sequence. We calculated perplexity by exponentiating the training loss (cross entropy loss) at the end of training for each fine-tuning method.
import pandas as pd
import numpy as np
# Load the training loss metrics
with open(f"{os.getcwd()}/content/Projects/supplemental/efficient_ft_llm/metrics/training_metrics.json", 'r', encoding='utf-8') as fp:
data = json.load(fp)
with open(f"{os.getcwd()}/content/Projects/supplemental/efficient_ft_llm/metrics/peft_metrics.json", 'r', encoding='utf-8') as fp:
metrics = json.load(fp)
# Load pre-computed eval and training metrics and add training loss and perplexity to
# eval metrics
for i, j in data.items():
method = '_'.join(i.split('_')[:-1])
if 'gemma' in method:
if '7b' in method:
model = 'google/gemma-7b'
elif '2b' in method:
model = 'google/gemma-2b'
elif 'llama2' in method:
model = 'meta-llama/Llama-2-7b-hf'
elif 'mistral' in method:
model = 'mistralai/Mistral-7B-v0.1'
if method not in metrics[model]:
metrics[model][method]={}
metrics[model][method]['loss'] = j[0]['loss']
metrics[model][method]['perplexity'] = np.exp(j[0]['loss']) # exponentiate loss to get perplexity
Metrics Plotting¶
Accross each model and method, each metric is plotted below.
for_plot = pd.DataFrame.from_dict({(i,j): metrics[i][j]
for i in metrics.keys()
for j in metrics[i].keys()},
orient='index')
for_plot = for_plot.reset_index().rename(columns={'level_0':'model', 'level_1':'method'})
for_plot['method'] = for_plot['method'].apply(lambda x: '_'.join(x.split('_')[2:4]))
for_plot['model'] = for_plot['model'].apply(lambda x: x.split('/')[1])
for_plot
import matplotlib.pyplot as plt
for i in ['avg_score', 'accuracy', 'throughput']:
d = for_plot[['model', 'method', i]].pivot_table(columns='method', index='model', values=i)
ax = d.plot.bar(rot=45)
ax.set_title(i)



References¶
- Z. Wan et al., “Efficient Large Language Models: A Survey,” arXiv (Cornell University), Dec. 2023. https://arxiv.org/abs/2312.03863.
- L. Xu, H. Xie, S.-Z. J. Qin, X. Tao, and F. L. Wang, “Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment,” arXiv.org, Dec. 19, 2023. https://arxiv.org/abs/2312.12148.
- Z. Liu et al., “Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time,” arXiv.org, Oct. 26, 2023. https://arxiv.org/abs/2310.17157
- D. Khashabi et al., “UnifiedQA: Crossing Format Boundaries With a Single QA System,” arXiv.org, Oct. 06, 2020. https://arxiv.org/abs/2005.00700.
- https://magazine.sebastianraschka.com/p/understanding-encoder-and-decoder
- E.J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large language models,” in Proc. Int. Conf. Learn. Representations, 2022. https://arxiv.org/abs/2106.09685.
- Q. Zhang et al., “Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning,” arXiv.org, Mar. 18, 2023. https://arxiv.org/abs/2303.10512
- L. Xu, H. Xie, S.-Z. J. Qin, X. Tao, and F. L. Wang, “Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment,” arXiv.org, Dec. 19, 2023. https://arxiv.org/abs/2312.12148.
- H. Liu, D. Tam, M. Mohammed, J. Mohta, T. Huang, M. Bansal, and C. Raffel, “Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning,” in Proc. Adv. Neural Inf. Process. Syst., 2022. https://arxiv.org/abs/2205.05638.
- X. Liu, Y. Zheng, Z. Du, M. Ding, Y. Qian, Z. Yang, and J. Tang, “GPT Understands, Too,” arXiv preprint 2021. https://arxiv.org/abs/2103.10385.
- Y. Leviathan, M. Kalman, and Y. Matias, “Fast Inference from Transformers via Speculative Decoding,” arXiv.org, May 18, 2023. https://arxiv.org/abs/2211.17192
- https://lambdalabs.com/blog/fine-tuning-metas-llama-2-on-lambda-gpu-cloud
- Q. Zhang et al., “Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning,” arXiv.org, Mar. 18, 2023. https://arxiv.org/abs/2303.10512
- https://huggingface.co/docs/peft/developer_guides/quantization
- https://huggingface.co/docs/peft/v0.10.0/en/package_reference/ia3#peft.IA3Config
- https://huggingface.co/spaces/evaluate-metric/accuracy
- https://medium.com/@mayurdhvajsinhjadeja/jaccard-similarity-34e2c15fb524
- https://www.databricks.com/blog/llm-inference-performance-engineering-best-practices
- https://towardsdatascience.com/deploying-large-language-models-vllm-and-quantizationstep-by-step-guide-on-how-to-accelerate-becfe17396a2
- https://medium.com/nlplanet/two-minutes-nlp-perplexity-explained-with-simple-probabilities-6cdc46884584
- https://huggingface.co/spaces/evaluate-metric/accuracy